
تقفز أمامنا بشكل متكرر أخبار جديدة عن إصدارات لـ ChatGPT وGemini وغيرهم من المساعدات الذكية التي تعد جزءً مهماً ضمن الذكاء الاصطناعي التوليدي Generative AI.
ولكن كيف لنا ان نقارن بينها ونفهم أيهما الأفضل؟ ما هي معايير المقارنة وكيف نختار الأنسب لنا، كيف نفهم كل عبارة تقنية تقال لنا حول النماذج الحديثة وقوتها و أدائها؟
أوردنا هذه المقالة بلغة بسيطة لنشرح آلية المقارنة وفهم المصطلحات التي ترد أمامنا بشكر متكرر.
المحاور الرئيسية:
المعايير الأساسية لمقارنة المساعدات الذكية
يمكن أخذ المعايير الأساسية على النحو التالي:
- الأداء Performance.
- المرونة Adaptability.
- حجم البيانات Data Size.
- التكلفة Cost.
- التحكم في الخصوصية Privacy Controls.
وسنشرخ كل واحدة على حدى.
1- الأداء Performance
يمكن فهم الأداء على انه السرعة مع الدقة, طبعاً هذه الزاوية التي ننظر منها, ويمكن النظر من زوايا أخرى كثيرة, مثلاً يمكن إقحام الزمن للبدا بالرد, أو ربط الاداء بالجودة وهي وجهات نظر متعددة أخرى.
أ- السرعة Speed
وهي سرعة توليد النموذج للنصوص أو الصور. يُقاس ذلك عادة بعدد الكلمات أو الرموز التي يولدها في الثانية الواحدة (Tokens per second).
نموذج مثل GPT4 معروف بسرعته في معالجة النصوص الكبيرة، ولكنه قد يكون أبطأ من بعض النماذج الأخرى في مهام معقدة.
ب- الدقة Accuracy
يشير إلى مدى جودة النموذج في تقديم مخرجات تتطابق مع النصوص أو الأوصاف المطلوبة. الدقة هنا تعتمد على كمية البيانات التي تم تدريب النموذج عليها.
على سبيل المثال، Google Gemini يستخدم نموذجًا محدثًا قادرًا على تقديم مخرجات دقيقة بشكل كبير.
2- المرونة Adaptability
مدى قدرة النموذج على التكيف مع مهام جديدة وتوليد محتوى يتناسب مع متطلبات مختلفة. مثلاً، LLaMA من Meta يُعتبر نموذجًا مفتوح المصدر، مما يسمح للمطورين بتخصيصه وفقًا لاحتياجات محددة، مما يجعله أكثر مرونة في العديد من التطبيقات.
3- حجم البيانات Data Size
يشير إلى كمية البيانات التي تم تدريب النموذج عليها. حجم البيانات يؤثر على القدرة على توليد مخرجات متنوعة وذات جودة عالية. نموذج GPT4، على سبيل المثال، تم تدريبه على كميات هائلة من البيانات المتنوعة، مما يعطيه ميزة في توليد نصوص مفصلة ومعقدة.
4- التكلفة Cost
التكلفة تتضمن تكلفة استخدام النموذج بالنسبة للشركات أو الأفراد، سواء كان ذلك من حيث الطاقة الحاسوبية المطلوبة أو تكلفة الترخيص.
نموذج مثل GPT4 يتطلب قدرات حسابية عالية مقارنة ببعض النماذج الأخرى مثل LLaMA 3 الذي يعتبر أقل تكلفة وأقل استهلاكًا للطاقة.
5- التحكم في الخصوصية Privacy Controls
بالنسبة للشركات التي تتعامل مع بيانات حساسة، يجب أن يوفر النموذج آليات للتحكم في الخصوصية وحماية البيانات. Google Gemini، على سبيل المثال، يقدم أدوات خاصة للمؤسسات تتيح لهم إدارة البيانات بطرق تحافظ على الخصوصية.
معايير أخرى تقنية للمقارنة
عند الحديث عن النماذج اللغوية الكبيرة Large Language Models مثل GPT-4 أو Gemini، هناك عدة مصطلحات تقنية يتم ذكرها بانتظام، من بينها البارامترات Parameters، آلية الانتباه Attention Mechanism، والسياق Context.
هذه المفاهيم هي أساسات رئيسية لنجاح وتطور نماذج الذكاء الاصطناعي التوليدي، وسنشرحها بالتفصيل هنا.
1- البارامترات Parameters
البارامترات هي المتغيرات التي تُحدد قوة ودقة النموذج الذكي.
في نماذج الذكاء الاصطناعي، البارامترات هي القيم التي يتم تعديلها أثناء تدريب النموذج وكلما زاد عدد البارامترات، زادت قدرة النموذج على فهم الأنماط المعقدة وتحليل البيانات بشكل أكثر تفصيلًا.
يمكن اعتبار البارامترات وكأنها نقاط قوة أو أوزان تحدد كيفية تفسير النموذج للمعلومات.
كيف تعمل البارامترات؟
عند إدخال جملة أو نص إلى نموذج الذكاء الاصطناعي، تمر الكلمات عبر شبكة عصبية مكونة من عدة طبقات وكل طبقة تحتوي على برامترات يتم تعديلها لتحسين دقة النتائج.
على سبيل المثال، GPT-3 يحتوي على حوالي 175 مليار برمتر، مما يسمح له بفهم النصوص المعقدة جدًا والتعامل مع تنوع لغوي واسع, أما النماذج الأكثر تقدمًا مثل GPT-4 فقد تحتوي على مليارات أخرى من البارامترات، مما يجعلها أكثر قوة.
ما هو تأثير زيادة عدد البارامترات؟
زيادة عدد البارامترات يحسّن قدرة النموذج على التعلم والتعميم. فكلما زادت البارامترات، أصبح النموذج أكثر قدرة على التعامل مع المهام المعقدة، مثل كتابة مقالات أو توليد أكواد برمجية.
ومع ذلك، فإن زيادة عدد البارامترات يؤدي إلى زيادة الحاجة إلى موارد حسابية أكبر، مثل وحدات معالجة الرسومات GPUs أو معالجات Tensor الخاصة بـ Google.
2- آلية الانتباه Attention Mechanism
آلية الانتباه هي تقنية تُستخدم في النماذج اللغوية لتحسين قدرتها على التعامل مع السياق الطويل والتركيز على أجزاء محددة من النص.
في السابق، كانت الشبكات العصبية تواجه صعوبات في التعامل مع النصوص الطويلة أو تذكر المعلومات القديمة في الجملة. ولكن مع آلية الانتباه، يمكن للنموذج أن “ينتبه” إلى الأجزاء المهمة من النص التي لها علاقة بالسياق الحالي.
كيف تعمل آلية الانتباه؟
تخيل أن النص طويل ومعقد، وتحتاج إلى ربط جملة حالية بمعلومة وردت في بداية النص.
هنا تأتي آلية الانتباه لتساعد النموذج في تحديد الكلمات أو الجمل الأكثر أهمية وتركيز الموارد الحسابية عليها.
على سبيل المثال، في جملة “محمد كتب رسالة إلى علي، ولكنه نسي أن يرسلها”، فإن آلية الانتباه تساعد النموذج في فهم أن الضمير “هو” يشير إلى “محمد” وليس “علي”.
ماهي آلية الانتباه متعددة الرؤوس Multi-Head Attention
هذا النوع من آلية الانتباه يستخدم في نماذج مثل Transformers، حيث يتم تقسيم الانتباه إلى عدة “رؤوس” تركز كل منها على جزء مختلف من النص. هذا يسمح للنموذج بفهم العلاقات بين الكلمات على مستويات متعددة.
على سبيل المثال، يمكن لرأس واحد التركيز على فهم القواعد النحوية بينما يركز رأس آخر على فهم العلاقات بين الكلمات في سياق النص وبالتالي فإن هذه التقنية تجعل النموذج أكثر قدرة على فهم النصوص المعقدة والمتعددة الأبعاد.
3- السياق Context
السياق في النماذج اللغوية يشير إلى قدرة النموذج على فهم النص بناءً على المعلومات التي سبق أن قرأها.
كلما كان النموذج قادرًا على الاحتفاظ بالسياق الأطول، كان أكثر قدرة على تقديم مخرجات دقيقة وملائمة.
على سبيل المثال، نماذج مثل GPT-4 قادرة على فهم ومعالجة النصوص الطويلة لأنها تستطيع الاحتفاظ بالسياق عبر آلاف الكلمات.
كيف يتم التعامل مع السياق الطويل؟
النماذج الحديثة مثل PaLM وGemini من Google تتفوق في التعامل مع السياق الطويل.
هذه النماذج يمكنها معالجة مستندات أو محادثات تمتد عبر عدة آلاف من الرموز (Tokens). هذا يعزز من قدرتها على إنتاج مخرجات دقيقة تلائم المعلومات التي وردت في بداية النص.
كيف تؤثر هذه المعايير التقنية على النتائج؟
1- الدقة والجودة:
كلما زاد عدد البارامترات وتحسنت آليات الانتباه، كانت النماذج أكثر قدرة على تقديم مخرجات دقيقة وذات جودة عالية.
2- التكيف مع المهام المختلفة:
النماذج التي تستخدم آليات الانتباه المتقدمة والسياق الطويل تكون أكثر ملاءمة للاستخدام في التطبيقات التي تتطلب تحليلاً دقيقًا مثل الطب، القانون، أو البرمجة.
3- التحديات التقنية:
زيادة عدد البارامترات وتحسين آلية الانتباه تزيد من تعقيد التدريب وتحتاج إلى موارد حسابية هائلة.
4- التحدي المستقبلي:
التحدي الرئيسي الآن هو كيفية تقليل استهلاك الموارد مع زيادة عدد البارامترات وتحسين آليات الانتباه. كذلك، تسعى الشركات إلى تطوير نماذج يمكنها الحفاظ على السياق الأطول دون الحاجة إلى قوة حسابية هائلة.
كيف نختار النموذج الأفضل لشركتنا
عند مقارنة نموذجين شهيرين أو أكثر من الذكاء الاصطناعي التوليدي لاختيار الأفضل لاحتياجاتك، هناك عدة عوامل يمكنك استخدامها كمعايير لتحديد النموذج الذي يناسبك أكثر.
سنشرح هنا بعض الخطوات التي يمكنك اتباعها لتقييم أي نموذج بشكل علمي ومبسط، مع ذكر المصطلحات التقنية المهمة:
1- نوع المهمة أو الاحتياج الأساسي
يجب أولاً تحديد نوع المهمة التي تريد استخدامها مع النموذج.
هل تحتاجه للتوليد النصي Text Generation، توليد الصور Image Generation، البرمجة Code Generation، أو تحليل البيانات؟ ولكل نموذج موجه نحو مهام محددة.
مثال:
نموذج GPT-4 من OpenAI ممتاز في الكتابة التلقائية وإنشاء المحتوى الإبداعي، بينما نموذج Gemini من Google ممتاز نحو الترجمة المتقدمة وتحليل البيانات الصناعية.
2- عدد البارامترات Parameters
عدد البارامترات يُحدد قدرة النموذج على استيعاب أنماط معقدة والتعامل مع كميات ضخمة من البيانات. كلما زاد عدد البارامترات، كان النموذج قادرًا على معالجة المهام الأكثر تعقيدًا، ولكن أيضًا يحتاج إلى موارد أكبر لتشغيله.
مثال:
نموذج مثل GPT-4 يحتوي على مئات المليارات من البارامترات، مما يجعله خيارًا قويًا للمهام المعقدة مثل إنشاء المقالات وتحليل النصوص.
في المقابل، إذا كنت بحاجة إلى نموذج أسرع وأقل تكلفة، فقد يكون نموذج مثل LLaMA خيارًا مناسبًا حيث يحتوي على برامترات أقل ويكون أكثر مرونة في الاستخدام اليومي.
3- آلية الانتباه Attention Mechanism
آلية الانتباه، وخاصةً آلية الانتباه متعدد الرؤوس Multi-head Attention، تُحسّن من قدرة النموذج على فهم السياق في النصوص الطويلة وتحليل الروابط بين الكلمات.
إذا كنت تتعامل مع نصوص أو محادثات طويلة، يجب أن تأخذ بعين الاعتبار مدى قدرة النموذج على الاحتفاظ بالسياق وفهمه.
مثال:
Google Gemini يستخدم آلية الانتباه المتقدمة لمعالجة النصوص الطويلة بدقة، مما يجعله مثاليًا للترجمة النصية أو تحليل المستندات الكبيرة.
4- التكلفة والأداء Cost and Performance
قد تحتاج إلى موازنة بين التكلفة والأداء. بعض النماذج تتطلب موارد حسابية كبيرة للعمل بكفاءة عالية، مما يجعلها مكلفة لاستخدام طويل الأمد.
مثال:
GPT-4 يتطلب موارد حسابية كبيرة جدًا بسبب عدد البارامترات الهائل، وهو مكلف لتطبيقات المؤسسات الكبرى. في المقابل، LLaMA هو نموذج مفتوح المصدر يتيح لك تعديل النماذج داخليًا بناءً على احتياجاتك وبأقل تكلفة.
5- التكامل Integration
ما مدى سهولة دمج النموذج مع التطبيقات التي تريد استخدامها؟ بعض النماذج تقدم أدوات دمج سلسة مع التطبيقات الموجودة مثل Google Cloud أو Microsoft Azure.
مثال:
Google Gemini يوفر تكاملًا سهلاً مع البنية التحتية السحابية لـ Google Cloud، مما يجعله خيارًا قويًا للشركات التي تعتمد على البنية السحابية لتخزين وتحليل البيانات.
في المقابل، OpenAI GPT-4 يمكن دمجه مع العديد من التطبيقات السحابية مثل Microsoft Azure لتمكين الشركات من استخدام الذكاء الاصطناعي عبر الأنظمة السحابية.
6- أمان البيانات والخصوصية Data Security and Privacy
إذا كنت تتعامل مع بيانات حساسة، يجب أن تأخذ بعين الاعتبار مدى قوة تدابير حماية البيانات التي يوفرها النموذج. بعض النماذج تقدم أدوات متقدمة لحماية الخصوصية وضمان أمان البيانات.
مثال:
Google Gemini يقدم ميزات متقدمة لإدارة البيانات الحساسة، مما يجعله خيارًا ممتازًا للشركات التي تحتاج إلى تطبيقات آمنة. في حين أن OpenAI GPT-4 يوفر أدوات متقدمة لتحليل البيانات لكنه قد يتطلب إعدادات إضافية لحماية البيانات الحساسة.
(المثال السابق قد لا يكون دقيق لأنه مصدره GPT وليس خبير تقني, وبالتالي يحتاج تأكد من خلال بحث تقني من شخص محترف).
7- القدرة على التعلم الذاتي Self-Learning
بعض النماذج يمكنها أن تتعلم وتتطور من التفاعلات مع المستخدمين، وهو أمر مهم إذا كنت تخطط لاستخدام الذكاء الاصطناعي لتحسين العمليات بمرور الوقت.
مثال:
GPT-4 يمتاز بقدرات تعلم معزز Reinforcement Learning، مما يعني أنه يمكن تحسين أدائه بناءً على ردود الفعل البشرية.
8- حجم السياق Context Size
هذا يشير إلى مدى قدرة النموذج على الاحتفاظ بالمعلومات حول النصوص الطويلة. كلما زاد حجم السياق الذي يستطيع النموذج معالجته، كان أكثر قدرة على فهم العلاقات المعقدة بين النصوص عبر فترات زمنية طويلة.
مثال:
GPT-4 يمكنه الاحتفاظ بالسياق عبر آلاف الرموز tokens مما يجعله مثاليًا لتحليل المحادثات الطويلة أو المقالات الكبيرة.
المقارنة من خلال أدوات جاهزة
هنالك أدوات ومواقع بدأت بالظهور لمقارنة النماذج المختلفة، ونورد هنا مثال أداة ArtificialAnalysis عبر الرابط من هنا.
يمكننا من خلال هذه الأداة مقارنة كل المعايير التي ذكرناها أعلاه.
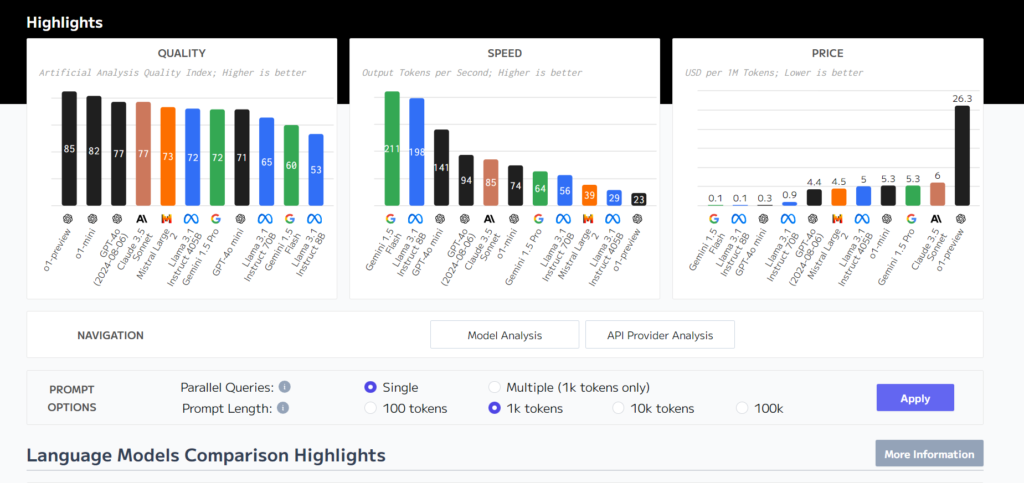
التحديات في تحسين هذه المعايير
التوسع في الأداء
مع تطور الذكاء الاصطناعي، يصبح تحسين السرعة والدقة أمرًا معقدًا.
تتطلب النماذج الكبيرة مثل GPT4 وGemini طاقة حسابية هائلة، ما يزيد من تكلفة التشغيل, والشركات تعمل على تطوير تقنيات مثل وحدات معالجة الرسومات GPUs ووحدات معالجة الموترات TPUs لتسريع العمليات وتحسين الأداء بتكلفة أقل.
التعلم العميق Deep Learning
يعتمد الكثير من التحسين على التعلم العميق والشبكات العصبية التي تستفيد من كميات ضخمة من البيانات لتعلم الأنماط وتحسين الأداء. ومع ذلك، فإن تحدي إدارة هذه الكميات الكبيرة من البيانات يبقى قائمًا.
الاستدامة Sustainability
مع تزايد الطلب على نماذج الذكاء الاصطناعي، هناك مخاوف متزايدة بشأن البصمة الكربونية لاستخدام الذكاء الاصطناعي في التطبيقات واسعة النطاق. بعض الشركات تعمل على تطوير حلول خضراء لاستخدام الطاقة بشكل أكثر كفاءة.
خلاصة أخيرة
هذه المفاهيم مثل البارامترات، آلية الانتباه، والسياق، ليست مجرد مصطلحات تقنية، بل هي مفتاح لفهم كيفية عمل نماذج الذكاء الاصطناعي التوليدي. تحسين هذه الجوانب سيساعد في تقديم نماذج أكثر دقة وكفاءة.
وعند مقارنة النماذج، يجب أن تحدد احتياجاتك بدقة. إذا كنت تحتاج إلى نموذج قوي جدًا في الكتابة والإبداع وتحليل النصوص الطويلة، أم إذا كنت تبحث عن نموذج متكامل مع البنية السحابية ولديك احتياجات صناعية أو ترجمة كبيرة مثلاً.