
المحاور الرئيسية:
نبذة عن النموذج الصيني DeepSeek
ديب سيك او DeepSeek هو نموذج ذكاء اصطناعي Artificial Intelligence-AI طورته شركة DeepSeek Artificial Intelligence Co. Ltd، وهي شركة صينية ناشئة متخصصة في تطوير تقنيات الذكاء الاصطناعي والتعلم العميق.
يُصنَّف ديب سيك كنموذج لغة كبير Large Language Model مصمم لمعالجة وفهم اللغة الطبيعية، مما يجعله قادرًا على أداء مجموعة متنوعة من المهام مثل الإجابة على الأسئلة، إنشاء النصوص، والترجمة.
برز DeepSeek كمنافس قوي لـ ChatGPT، الذي يحظى بانتشار واسع، حيث يقدم منظورًا جديدًا في عالم نماذج الذكاء الاصطناعي اللغوية.
وباعتباره بديلاً مفتوح المصدر، فقد جذب DeepSeek اهتمامًا كبيرًا بفضل قدراته المتميزة ونهجه الاقتصادي الفعّال، لا سيما في المجالات التقنية والرياضية.
وبينما يحافظ ChatGPT على مكانته بفضل ميزاته المتعددة وواجهته سهلة الاستخدام، فإن ظهور DeepSeek يمنحنا سببًا وجيهًا للنظر إليه كخيار جاد يستحق التجربة.
ما أثره على السوق العالمي؟
ديب سيك DeepSeek أثار تساؤلات المستثمرين وهز سوق الذكاء الاصطناعي، فرغم الغموض الذي يحيط بـ DeepSeek، فقد دفع المستثمرين إلى إعادة التفكير في كل ما كانوا يعتقدون أنهم يعرفونه عن الذكاء الاصطناعي.
تم تطوير التطبيق بتكلفة لا تتجاوز بضعة ملايين من الدولارات (بحسب زعم الشركة المطورة)، أي بفارق مليارات الدولارات مقارنةً بالنماذج الأمريكية مثل OpenAI.
كما أن المشروع تم بدون الاعتماد على أحدث الرقائق الإلكترونية التي تستهلك كميات هائلة من الطاقة، على الأقل وفقًا للتقارير المتاحة، رغم أن هذه التفاصيل لم يتم تأكيدها بعد.
لا تزال هناك العديد من التساؤلات حول كيفية نجاح هذه الشركة الناشئة في تحقيق هذا الإنجاز.
لكن مجرد فكرة أن الذكاء الاصطناعي يمكن إنتاجه بتكلفة أقل، أحدثت اضطرابًا في سوق الذكاء الاصطناعي.
تأثير DeepSeek على كبرى شركات التكنولوجيا
خذ على سبيل المثال شركة Nvidia (NVDA)، هل يمكنها الاستمرار في فرض أسعار مرتفعة على رقائقها إذا لم تكن تقنيتها الأفضل هي التي تقف وراء DeepSeek؟
مجرد هذا التساؤل تسبب في ما يلي:
إنفيديا Nvidia تخسر 600 مليار دولار من قيمتها السوقية:
شهدت أسهم Nvidia (NVDA) انخفاضًا بنسبة 17% بعد الإعلان عن DeepSeek، مما أدى إلى خسارة ضخمة تُقدر بـ 600 مليار دولار من قيمتها السوقية.
السبب الرئيسي لهذا التراجع هو المخاوف من أن تقنيات DeepSeek قد تقلل الطلب على الرقائق المتطورة التي تنتجها Nvidia، خاصة إذا كان النموذج الصيني قادرًا على العمل دون الحاجة إلى هذه الشرائح باهظة الثمن.
تراجع أسهم شركات الحوسبة السحابية والذكاء الاصطناعي
لم تقتصر الخسائر على Nvidia فقط، بل امتدت إلى شركات مراكز البيانات والذكاء الاصطناعي الكبرى مثل:
- مايكروسوفت Microsoft (MSFT): تأثرت بسبب المخاوف من أن DeepSeek قد يُوفر بديلاً أقل تكلفة لنماذج الذكاء الاصطناعي السحابية مثل Copilot و Azure AI.
- امازون Amazon (AMZN): تأثرت خدماتها السحابية AWS بسبب المخاوف من أن DeepSeek قد يقلل من الحاجة إلى بنية تحتية ضخمة لتشغيل نماذج الذكاء الاصطناعي.
- الشركة الأم لـ Google شركة Alphabet: انخفضت أسهمها بسبب احتمالية أن DeepSeek قد يشكل تهديدًا على نماذج الذكاء الاصطناعي الخاصة بها مثل Gemini.
تأثير على قطاع الطاقة
كانت هناك توقعات سابقة بأن الطلب المتزايد على الذكاء الاصطناعي سيؤدي إلى استهلاك هائل للطاقة، مما دفع بعض المستثمرين للاستثمار في شركات الطاقة مثل Constellation Energy وVistra و Talen Energy.
ولكن، إذا كان DeepSeek قادرًا على تحقيق أداء عالٍ دون الحاجة إلى استهلاك طاقة ضخم، فإن هذا قد يحدّ من الارتفاع المتوقع في الطلب على الكهرباء، مما تسبب في تراجع أسهم هذه الشركات بنسبة تتراوح بين 2% إلى 5%.
للمزيد من التفاصيل، يمكنك قراءة المقال الأصلي من رويتر.
ما الذي يميز البنية الداخلية لـ DeepSeek؟
يمتاز ديب-سيك ببنية مختلفة عن ChatGPT بمفاصل جوهرية وذلك طبقاً للمعلومات المتاحة لنا عبر الإنترنت، ومع ذلك لا ينفي أن ChatGPT قد يكون اعتمد ما سنقوم بشرحه.
المفاصل الجوهرية التي تميز ديب-سيك هي:
- مزيج الخبراء MoE.
- الانتباه الكامن متعدد الرؤوس MLA.
- التنبؤ بالرموز المتعددة MTP.
- استراتيجية الموازنة الخالية من الخسائر Auxiliary-Loss-Free Balancing Strategy.
- التدريب منخفض الدقة Low-precision training.
وهذا ما حصلنا عليه من معلومات حول الإصدار DeepSeek-v3 وليس الإصدار الأخير DeepSeek-R.
سنقوم بشرح هذه التقنيات والمنهجيات في الفقرات التالية.
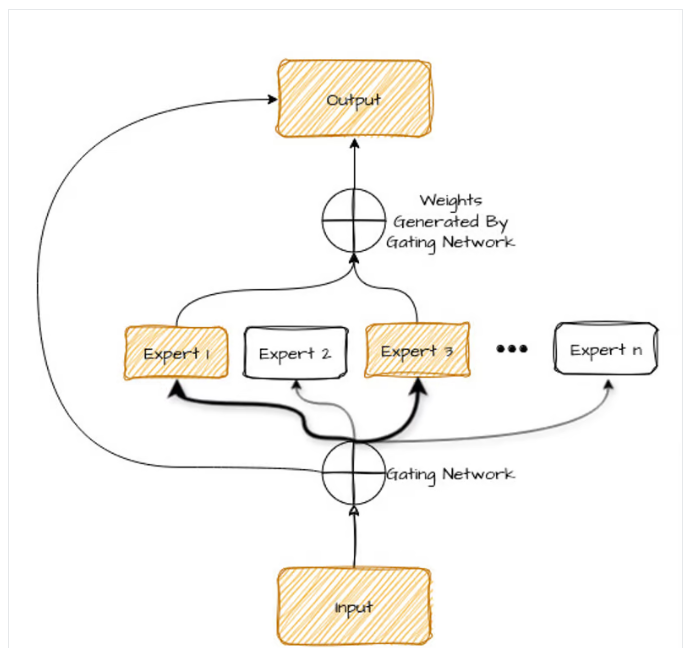
1- مزيج الخبراء MoE
يجب أن نعلم أن هذا المصطلح وهذه البنية ليست بالامر الجديد فهي موجودة وموثقة منذ عام 1991 ولكن العبرة تأتي بالتطبيق الهندسي المناسب للحصول على النتائج المرضية.
كي نفهما، لنتخيل نموذج الذكاء الاصطناعي كفريق من المتخصصين، كل منهم لديه خبرته الفريدة.
يعمل نموذج مزيج الخبراء MoE على هذا المبدأ من خلال تقسيم مهمة معقدة بين شبكات أصغر متخصصة تُعرف باسم “الخبراء”.
يركّز كل خبير على جانب معين من المشكلة، مما يمكّن النموذج من معالجة المهمة بكفاءة ودقة أكبر.
إنه يشبه وجود طبيب للقضايا الطبية، وميكانيكي لمشاكل السيارات، وطاهٍ للطهي، كل خبير يتعامل مع ما يجيده بشكل أفضل.
من خلال التعاون، يمكن لهؤلاء المتخصصين حل مجموعة أوسع من المشاكل بشكل أكثر فعالية من أخصائي عام واحد.
مثال واقعي:
تخيل أنك تسأل نموذج DeepSeek ما هي الوجبة المثالية لشخص مصاب بمرض السكري؟
بدلاً من أن يعالج النموذج السؤال كوحدة واحدة، سيستخدم مزيج الخبراء MoE لتوزيع المهمة على عدة “خبراء” داخليين متخصّصين، بحيث يحصل كل خبير على جزء معين من السؤال بناءً على اختصاصه:
- الخبير الأول: أخصائي التغذية.
- الخبير الثاني: الطبيب المختص.
- الخبير الثالث: الطاهي المتمرس.
- الخبير الرابع: أخصائي أسلوب الحياة.
ثم يتم بناء الإجابة على النحو التالي:
- كل خبير يعالج جزءه من السؤال بناءً على معرفته المتخصصة.
- يتم دمج إجابات الخبراء معًا لتقديم إجابة نهائية شاملة تجمع بين الدقة الطبية، القيمة الغذائية، والنصائح العملية.
- يتم تقديم الإجابة للمستخدم بطريقة سلسة ومترابطة، وكأنها جاءت من خبير واحد شامل، بينما في الواقع، هي نتاج تعاون مجموعة من “الخبراء” داخل النموذج.
تتمثل مزايا استخدام MoE في:
- الكفاءة: يتم استخدام الخبراء الذين يجيدون جزءًا معينًا من المشكلة فقط، مما يوفر الوقت وقوة الحوسبة.
- المرونة: يمكنك بسهولة إضافة المزيد من الخبراء أو تغيير تخصصاتهم، مما يجعل النظام قابلاً للتكيف مع مشاكل مختلفة.
- نتائج أفضل: نظرًا لأن كل خبير يركز على ما يجيده، فإن الحل الإجمالي يكون عادةً أكثر دقة وموثوقية.
تجدون شرح تفصيلي عن الموضوع في هذه المقالة التي تبسّط المعلومة.
2- الانتباه الكامن متعدد الرؤوس MLA
أولاً لنعلم أن نماذجي الذكاء الاصطناعي التي تعالج النصوص واللغات الطبيعية، فهي تستخدم ما نسميه الانتباه Attention وهو يُطبّق كعملية واحدة فقط، مما يجعل النموذج يركز على جزء واحد من الجملة في كل مرة.
لكن مع تطور النماذج ظهرت تقنية الانتباه متعدد الرؤوس Multi-Head Attention – MHA، بحيث يمكن للنموذج أن ينظر إلى عدة أجزاء مختلفة من النص في نفس الوقت، مما يسمح له بفهم السياق بشكل أعمق وأسرع.
المشكلة،
رغم ما سبق فإن النماذج التي تستخدم الانتباه متعدد الرؤوس بدأت تواجه تحد كبير وهو الاستهلاك الضخم للذاكرة والقدرة الحاسوبية أثناء معالجة النصوص الطويلة.
لحل هذه المشكلة،
ظهر Multi-Head Latent Attention (MLA) كطريقة مبتكرة لجعل هذه النماذج أكثر كفاءة وأقل استهلاكا للموارد، دون التأثير على جودتها في فهم النصوص وإنتاجها.
بدلاً من الاحتفاظ بجميع البيانات التي يحتاجها النموذج أثناء معالجته للنص، يقوم MLA بضغط المعلومات المهمة وتخزينها في شكل تمثيلات “كامنة” Latent Representations.
هذه التقنية تقلل من الحاجة إلى تخزين كميات هائلة من المعلومات المؤقتة، مما يجعل الذكاء الاصطناعي يعمل بسرعة أكبر وبكفاءة أعلى.
بعبارة أخرى،
تخيل أنك تدرس موضوعًا معقدًا، ولكنك تحتفظ بكل الملاحظات والتفاصيل الدقيقة في دفترك، مما يجعل الدفتر ضخمًا وصعب التصفح.
بدلاً من ذلك، تقوم بتلخيص المعلومات المهمة فقط، بحيث يصبح لديك ملخص ذكي يساعدك على استرجاع المعلومات بسرعة وبدقة دون الحاجة إلى حفظ كل التفاصيل.
هذا بالضبط ما يفعله MLA فهو يسمح للنموذج بالحفاظ على المعلومات المهمة فقط، مما يجعله أسرع وأكفأ دون التأثير على جودة المخرجات.
3- التنبؤ بالرموز المتعددة MTP
في النماذج القديمة يتم توليد كلمة واحدة في كل خطوة، ثم يتم إدخالها مجددًا للنموذج لتوليد الكلمة التالية وهكذا.
يعني تصور انك تكتب مقالة، وتعيد قراءة النص مع كل كلمة جديدة تكتبها، تتوقف تعيد القراءة والتقييم, ثم تكتب الكلمة الجديدة وهكذا.
هذا يجعل العملية بطيئة، حيث أن النموذج يحتاج إلى عدة خطوات لإنشاء جملة كاملة.
النهج المسمى بالتنبؤ متعدد الرموز Multi-token prediction MTP، يغير الطريقة التقليدية في تنبأ الكلمات التالية ضمن النصوص من خلال جعل النموذج يتنبأ بعدة كلمات مستقبلية في وقت واحد بدلاً من كلمة واحدة فقط.
في كل موضع في الجملة، يستخدم النموذج مسارات تنبؤ متعددة، أو “رؤوس”، للتنبؤ بالكلمات العديدة التالية في وقت واحد، والعمل بشكل تعاوني لتحسين الكفاءة والتماسك.
4- استراتيجية الموازنة الخالية من الخسائر ALFBS
هي تقنية تُستخدم في تدريب نماذج الذكاء الاصطناعي، وخاصة في نماذج مزيج الخبراء MoE، بهدف تحقيق توازن مثالي في تنشيط “الخبراء” داخل النموذج دون الحاجة إلى إضافة وظائف خسارة إضافية Auxiliary Losses.
في نماذج MoE، يتم توزيع المهام على وحدات متعددة تُعرف بـ “الخبراء “Experts، بحيث يُفترض أن يعمل كل خبير على جزء معين من البيانات.
المشكلة أن بعض الخبراء قد يكونون أكثر تحميلًا من غيرهم، مما يؤدي إلى عدم توازن في توزيع الحسابات، وبالتالي انخفاض كفاءة التدريب وزيادة استهلاك الموارد.
عادةً، يتم التعامل مع هذه المشكلة بإضافة خسارة مساعدة Auxiliary Loss، والتي تجبر النموذج على تحقيق توزيع متوازن للمهام بين الخبراء.
ولكن هذه الطريقة قد تؤدي إلى مشكلات في استقرار التدريب، وقد تؤثر على جودة أداء النموذج.
هنا تأتي إستراتيجية Auxiliary-Loss-Free Balancing Strategy كبديل أكثر كفاءة.
يتم توجيه البيانات إلى الخبراء الأقل تحميلًا بشكل ذكي، مما يضمن أن جميع الخبراء يحصلون على كمية متساوية من العمل بمرور الوقت.
هذا يقلل من الحاجة إلى موارد إضافية ويجعل عملية التدريب أكثر استقرارًا والنتيجة هي:
- توازن طبيعي بين الخبراء دون الحاجة إلى خسائر إضافية.
- تحسين كفاءة الحسابات وتقليل الحمل الزائد على بعض الخبراء.
- تدريب أكثر استقرارًا، حيث لا يتم إجبار النموذج على توازن غير طبيعي عبر خسائر إضافية
- تحسين الأداء العام للنموذج، مما يؤدي إلى استدلال أسرع وجودة أعلى في المخرجات.
5- التدريب منخفض الدقة Low-precision training
التدريب منخفض الدقة هو تقنية أساسية في الذكاء الاصطناعي الحديث، تتيح تسريع العمليات الحسابية وتقليل استهلاك الموارد دون التضحية بالدقة بشكل كبير.
في النماذج التقليدية، تتم جميع العمليات الحسابية باستخدام أعداد بفاصلة عائمة Floating-Point Numbers عالية الدقة مثل:
- FP32 (32-bit floating point)
- FP64 (64-bit floating point)
ولكن، عند استخدام دقة أقل مثل:
- FP16 (16-bit floating point)
- BF16 (Brain Floating Point 16-bit)
- INT8 (8-bit integer)
فإن العمليات الحسابية تصبح أسرع وأقل استهلاكًا للذاكرة، مع الحفاظ على دقة كافية (وليست عالية) لمعظم التطبيقات.
النتيجة النهائية او الفوائد ستكون:
- تسريع التدريب: العمليات الحسابية تصبح أسرع، مما يقلل من وقت تدريب النماذج الكبيرة.
- تقليل استهلاك الذاكرة: يسمح بتدريب نماذج أكبر على نفس الأجهزة.
- خفض استهلاك الطاقة: مما يجعله مثاليًا لتدريب النماذج على نطاق واسع.
الخاتمة وملخص مفيد عن DeepSeek
يأتي نموذج DeepSeek ليغيّر مشهد الذكاء الاصطناعي بطريقة جذرية، حيث يطرح نهجًا جديدًا أكثر كفاءة وأقل تكلفة مقارنة بالنماذج التقليدية مثل ChatGPT.
من خلال تقنيات مبتكرة مثل مزيج الخبراء MoE، والانتباه الكامن متعدد الرؤوس MLA، والتنبؤ بالرموز المتعددة MTP، أصبح بالإمكان تحسين سرعة الاستدلال وتقليل استهلاك الموارد دون التضحية بجودة النتائج.
أهم الدروس المستفادة من DeepSeek:
- كفاءة أفضل: استخدام تقنيات التدريب منخفض الدقة والموازنة الذكية للخوارزميات، مما يقلل استهلاك الطاقة والموارد الحاسوبية.
- توزيع ذكي للمهام: من خلال MoE، يتم تنشيط “الخبراء” بناءً على الحاجة، مما يجعل النموذج أكثر كفاءة واستجابة.
- قدرة تنافسية قوية: نجاح DeepSeek في إحداث تأثير فوري على السوق، كما رأينا في تراجع أسهم شركات كبرى مثل Nvidia وMicrosoft، يعكس مدى خطورة التحولات القادمة في الذكاء الاصطناعي.
ما التالي؟
يبقى السؤال الأهم، هل سيؤدي DeepSeek إلى إعادة تعريف كيفية بناء نماذج الذكاء الاصطناعي، أم أنه مجرد موجة عابرة؟
إذا تمكنت الشركات من تبني هذه التقنيات الجديدة، فقد نشهد عصرًا جديدًا من نماذج الذكاء الاصطناعي الأسرع، الأكثر كفاءة، والأقل تكلفة، مما قد يؤدي إلى ثورة حقيقية في الذكاء الاصطناعي العالمي.