
ليست لمعالجة الألعاب الحاسوبية فقط، بل هي عملاق الحوسبة المتوازية، والمشغّل الخارق لخوارزميات الذكاء الاصطناعي (AI).
ربما سمعت عن وحدات الـ GPU في سياق الألعاب الإلكترونية، لكن دورها في الذكاء الاصطناعي أعمق بكثير.
ولكن لماذا تعتبر هذه الوحدة العمود الفقري لمعالجة الذكاء الاصطناعي؟
المحاور الرئيسية:
ما هي الـ GPU؟
وحدة معالجة الرسومات GPU (graphics processing unit) هي دائرة إلكترونية متخصصة مصممة لمعالجة وتحويل الرسوميات بكفاءة.
نشأت في البداية لتسريع عملية عرض ومعالجة الرسوميات في الألعاب الإلكترونية، حيث تحتاج الرسوميات ثلاثية الأبعاد إلى معالجة بيانات معقدة وسريعة لتقديم صور واقعية وسلسة.
ومن هنا جاء اسم “وحدة معالجة الرسومات”، كونها مخصصة للتعامل مع الرسوميات (Graphics).

تاريخ النشأة
تعود بداية ظهور الـ GPU بشكل جلي في التسعينيات، مع إصدار شركة NVIDIA لأول وحدة معالجة رسومات مخصصة في عام 1999 تحت اسم “GeForce 256”.
هذه الوحدة كانت الأولى من نوعها التي قدمت ميزة تسريع الرسوميات بشكل مستقل عن وحدة المعالجة المركزية (CPU)، مما سمح بتجربة ألعاب أسرع وأكثر سلاسة.
ومع مرور الوقت، أدرك الباحثون والعلماء أن هذه القدرة على معالجة البيانات بكفاءة يمكن أن تُستغل في تطبيقات أخرى تتطلب قدرات حسابية كبيرة، ومنها الذكاء الاصطناعي.
الكفاءة الهندسية لوحدة معالجة الرسومات (GPU) مع الذكاء الاصطناعي
لنفهم لماذا تعتبر الـ GPU العمود الفقري لمعالجة للذكاء الاصطناعي، يجب أن نعود إلى أساسيات كيفية عمل الذكاء الاصطناعي.
معظم خوارزميات الذكاء الاصطناعي تعتمد على الشبكات العصبية العميقة (Deep Neural Networks)، والتي تتطلب معالجة كميات هائلة من البيانات وإجراء ملايين العمليات الحسابية بشكل متوازي، أي بآن واحد معاً وغير متسلسل.
مرة أخرى، العمل على التوازي، وليس العمل لكل مهمة تلو الأخرى.
هنا تأتي الـ GPU لتلعب دورًا عظيماً، ولنضع في بالنا أن العمليات الحسابية أغلبها تجرى على المصفوفات، وأغلب العمليات على المصفوفات يمكن أن تنجز بشكل متوازي وليس متسلسل.
على عكس وحدات المعالجة المركزية (CPU)، التي تتكون عادة من عدد محدود من النوى القوية المصممة لتنفيذ سلسلة من التعليمات بشكل متسلسل، فإن وحدات GPU تحتوي على آلاف النوى الأصغر التي يمكنها تنفيذ العديد من التعليمات في وقت واحد.
هذا التصميم المتوازي يجعل الـ GPU مثالية لتدريب الشبكات العصبية العميقة (Deep Neural Networks) ومعالجة كميات هائلة من البيانات.
خصائص هندسية تتمتع بها شرائح الـ GPU
1- التوازي الهائل (Massive Parallelism):
بدايةً الحوسبة المتوازية Parallel computing هي نوع من الحوسبة يتم فيها تنفيذ العديد من الحسابات أو العمليات في وقت واحد.
يمكن تقسيم المهام أو المشكلات الكبيرة غالبًا إلى مشكلات أصغر، والتي يمكن حلها في نفس الوقت.
تتكون وحدات GPU من مئات أو آلاف النوى (Cores) التي تعمل بشكل متزامن.
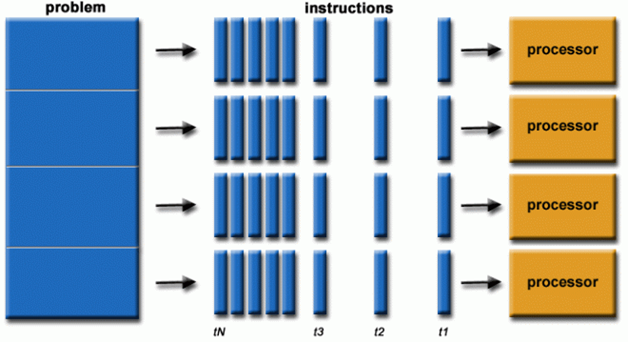
هذه النوى تُستخدم لتنفيذ آلاف العمليات الحسابية في آن واحد، مما يعزز من سرعة معالجة البيانات الضخمة، وهو ما يتطلبه الذكاء الاصطناعي عند التعامل مع الشبكات العصبية.
على سبيل المثال، عند تدريب شبكة عصبية، يجب حساب نواتج الآلاف أو حتى الملايين من الاتصالات العصبية في نفس الوقت، وهو ما يمكن لوحدة GPU التعامل معه بكفاءة عالية.
2- ذاكرة عرض النطاق العريض (High-Bandwidth Memory):
تصور امتلاك وحدة معالجة فائقة السرعة، ولكنها متصلة بذاكرة بطيئة لتبادل البيانات، حينها ستذهب سرعة المعالجة هباءً منثوراً.
وسرعة الذاكرة تأتي من سرعة نقل البيانات مع سرعة تخزينها وتبادلها، الكل معاً، ويعبّر عن ذلك بتقبلها لترددات عالية وعرض حزمة كبير.
ومن هنا نفهم أن الذاكرة ذات النطاق الترددي العالي (HBM) هي نوع من ذاكرة الكمبيوتر مصممة لتوفير النطاق الترددي العالي واستهلاك الطاقة المنخفض.
وعادةً ما تكون مناسبة للاستخدام في تطبيقات الحوسبة عالية الأداء حيث تكون سرعة البيانات مطلوبة.
تتمتع وحدات GPU بذاكرة ذات عرض نطاق عالٍ، مما يتيح نقل كميات كبيرة من البيانات بين الذاكرة والمعالج بسرعة فائقة.
هذا يقلل من زمن الوصول ويزيد من سرعة تنفيذ العمليات الحسابية المطلوبة في تدريب النماذج الذكاء الاصطناعي.
النماذج الكبيرة تحتاج إلى تدفق مستمر وسريع من البيانات خلال مراحل التدريب، وهو ما توفره الـ GPU بفضل هندستها الفريدة.
3- معمارية SIMD وSIMT:
وحدات GPU تعتمد على كلا بنية المعالجة:
- تعليمات وحيدة بيانات متعددة Single Instruction, Multiple Data SIMD.
- تعليمة واحدة، خيوط أو ثريدات متعددة Single Instruction, Multiple Threads SIMT.
حيث يمكن تنفيذ نفس التعليمات على مجموعة كبيرة من البيانات في وقت واحد.
هذه البنية مثالية لمعالجة العمليات الرياضية المتكررة والمكثفة التي تشكل جوهر العمليات في الشبكات العصبية، مثل عمليات الضرب المصفوفي التي تشكل جزءًا كبيرًا من حسابات الشبكة العصبية.
بفضل هذه الخصائص الهندسية، تستطيع وحدات GPU تحسين أداء الذكاء الاصطناعي بشكل كبير مقارنة بوحدات المعالجة التقليدية.
هذه الكفاءة تعني أنه يمكن تدريب نماذج أكبر وأعمق في وقت أقل، مما يفتح الباب أمام تطبيقات أكثر تقدمًا وقوة في مجال الذكاء الاصطناعي.
تطبيقات استخدام GPU في الذكاء الاصطناعي
تجد وحدات الـ GPU تطبيقاتها في العديد من المجالات التي تعتمد على الذكاء الاصطناعي.
من تدريب النماذج إلى تشغيل التطبيقات الذكية في الوقت الحقيقي، أصبحت الـ GPU جزءًا لا يتجزأ من تطوير الذكاء الاصطناعي الحديث.
أمثلة على التطبيقات:
1- تدريب الشبكات العصبية:
يتطلب تدريب النماذج الكبيرة، مثل تلك المستخدمة في التعرف على الصور أو معالجة اللغة الطبيعية، استخدام وحدات GPU لتسريع العملية وتقليل الوقت اللازم لتحقيق نتائج دقيقة.
2- القيادة الذاتية:
تستخدم السيارات ذاتية القيادة وحدات GPU لمعالجة كميات هائلة من البيانات الحية، مثل الصور من الكاميرات والمعلومات من أجهزة الاستشعار، لاتخاذ قرارات فورية.
3- التصوير الطبي:
في الطب، تُستخدم وحدات GPU لتسريع تحليل الصور الطبية، مما يساعد في تشخيص الأمراض بسرعة ودقة أكبر.
المشاريع الكبيرة المتموضعة فيها GPU
الوحدات المعالجة الرسومية (GPU) أصبحت جزءًا أساسيًا في العديد من المشاريع الكبيرة التي تهدف إلى استخدام الذكاء الاصطناعي في حل مشكلات معقدة.
أمثلة على المشاريع:
1- مشروع الذكاء الاصطناعي في الفضاء:
في الذكاء الاصطناعي المدمج مع صناعة الفضاء، نجد أن وكالات الفضاء مثل ناسا تستخدم وحدات GPU لتحليل البيانات الضخمة المستمدة من المركبات الفضائية والتلسكوبات، مما يساعد في اكتشافات علمية جديدة.
2- شبكات التعلم العميق:
تستخدم شركات التكنولوجيا الكبرى مثل Google وFacebook وحدات GPU لتدريب شبكات التعلم العميق الخاصة بها، التي تشغل تطبيقات مثل محركات البحث، الترجمة الفورية، والتعرف على الصور.
الاتجاهات المستقبلية
جامعة ستانفورد وفي تقريرها الأخير عن الذكاء الاصطناعي، ذكرت أن أداء وحدات GPU “زاد بنحو 7000 مرة” منذ عام 2003 وأن السعر لكل أداء “أكبر بنحو 5600 مرة”.
مما سبق نرى أن الحاجة والطلب متزايد بشكل أسّي وليس طردي.
1- دمج الذكاء الاصطناعي داخل وحدات GPU:
من المتوقع أن تشهد السنوات المقبلة تطورًا في وحدات GPU بحيث يتم دمج خوارزميات الذكاء الاصطناعي داخلها، مما سيسمح بتحقيق أداء أعلى وكفاءة أكبر.
تصور أن يكون تدفق البيانات ومعالجتها يتغير بطبيعته وشكله بحسب ما يمليه الذكاء الاصطناعي داخل شريحة المعالجة، حقيقة سيكون ثورة كبيرة في تحسين الأداء.
2- تحسين كفاءة الطاقة:
مع تزايد أهمية الاستدامة، يعمل المصنعون على تطوير وحدات GPU تكون أكثر كفاءة في استهلاك الطاقة، مما يقلل من تأثيرها البيئي.
من يسيطر على إنتاج وحدات GPU اليوم؟
اليوم، تسيطر شركتا NVIDIA وAMD على سوق وحدات GPU، حيث تستثمر كل منهما بشكل كبير في البحث والتطوير لتحسين أداء وحداتها.
تركز NVIDIA بشكل خاص على تطوير وحدات مخصصة للذكاء الاصطناعي، بينما تتوسع AMD في مجالات الحوسبة العلمية والألعاب.
التنافس بين NVIDIA و AMD
NVIDIA:
تُعد الرائدة في مجال تطوير وحدات GPU المخصصة للذكاء الاصطناعي، مع إصدار وحدات متقدمة مثل A100 التي تعتبر خيارًا رئيسيًا للمشاريع الضخمة.
AMD:
تواصل AMD تحسين وحداتها المنافسة مثل Instinct MI100، وتستهدف سوق الحوسبة العلمية والشركات الكبرى التي تحتاج إلى حلول قوية وفعالة.
الأبحاث الحالية حول GPU
البحث والتطوير في مجال وحدات GPU لا يتوقف. تركز الأبحاث الحالية على تحسين أداء الوحدات وتقليل استهلاك الطاقة، بالإضافة إلى دمج المزيد من الذكاء الاصطناعي داخل الوحدات نفسها.
أمثلة على الأبحاث:
1- التحسين المتقدم للحوسبة المتوازية:
تركز الأبحاث على كيفية تحسين أداء وحدات GPU في تنفيذ العمليات المتوازية، مما يزيد من سرعتها وفعاليتها في معالجة البيانات.
2- تقليل استهلاك الطاقة:
تُجرى الأبحاث حاليًا على تطوير وحدات GPU تكون أكثر كفاءة في استهلاك الطاقة، مما يجعلها أكثر ملاءمة للاستخدام في التطبيقات الكبيرة والمستدامة.
كلمة أخيرة
يجب أن نعلم أن كل البرمجيات مهما تطورت فهي بلا فائدة بدون وحدات المعالجة، بالتالي سيكون التطوير عليها والسيطرة على أسواقها هو اليد العليا في السباق التقني.
حتى تمت تسمية وحدات معالجة الرسوميات GPU بالمعادن الأرضية النادرة، لأنها تشكل الأساس لعصر الذكاء الاصطناعي التوليدي اليوم .
تظل وحدات GPU أداة أساسية في تشكيل مستقبل التكنولوجيا والذكاء الاصطناعي. ومع استمرار التطورات في هذا المجال، لا شك أن الـ GPU ستظل في طليعة الابتكار التكنولوجي لسنوات قادمة.